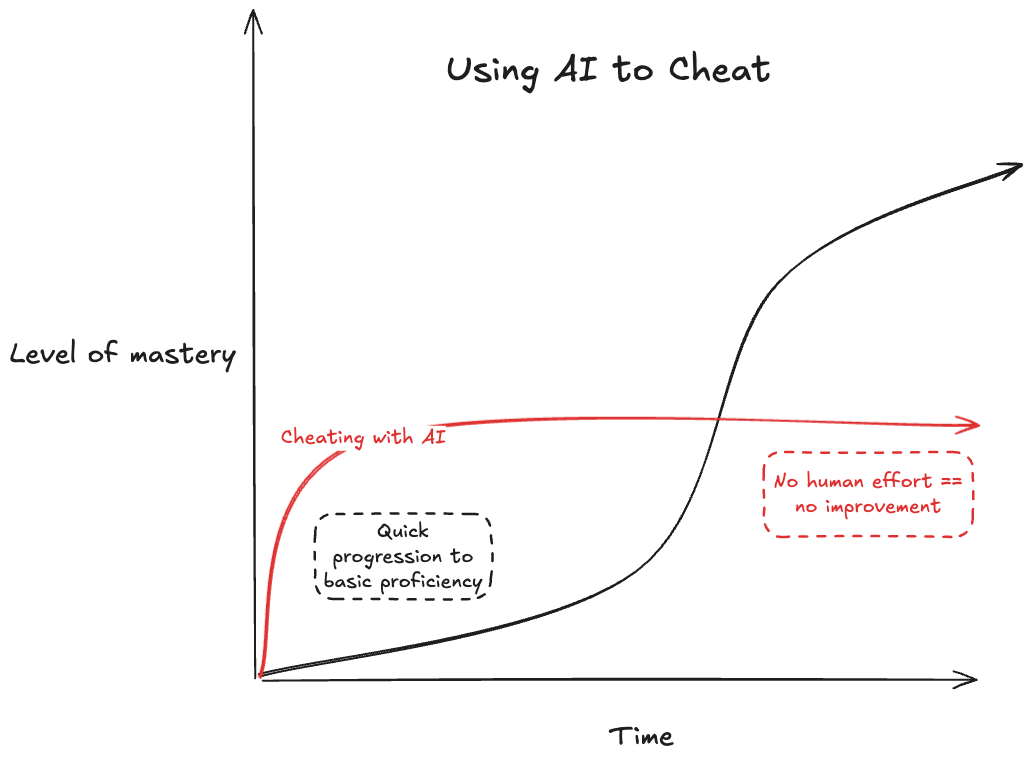
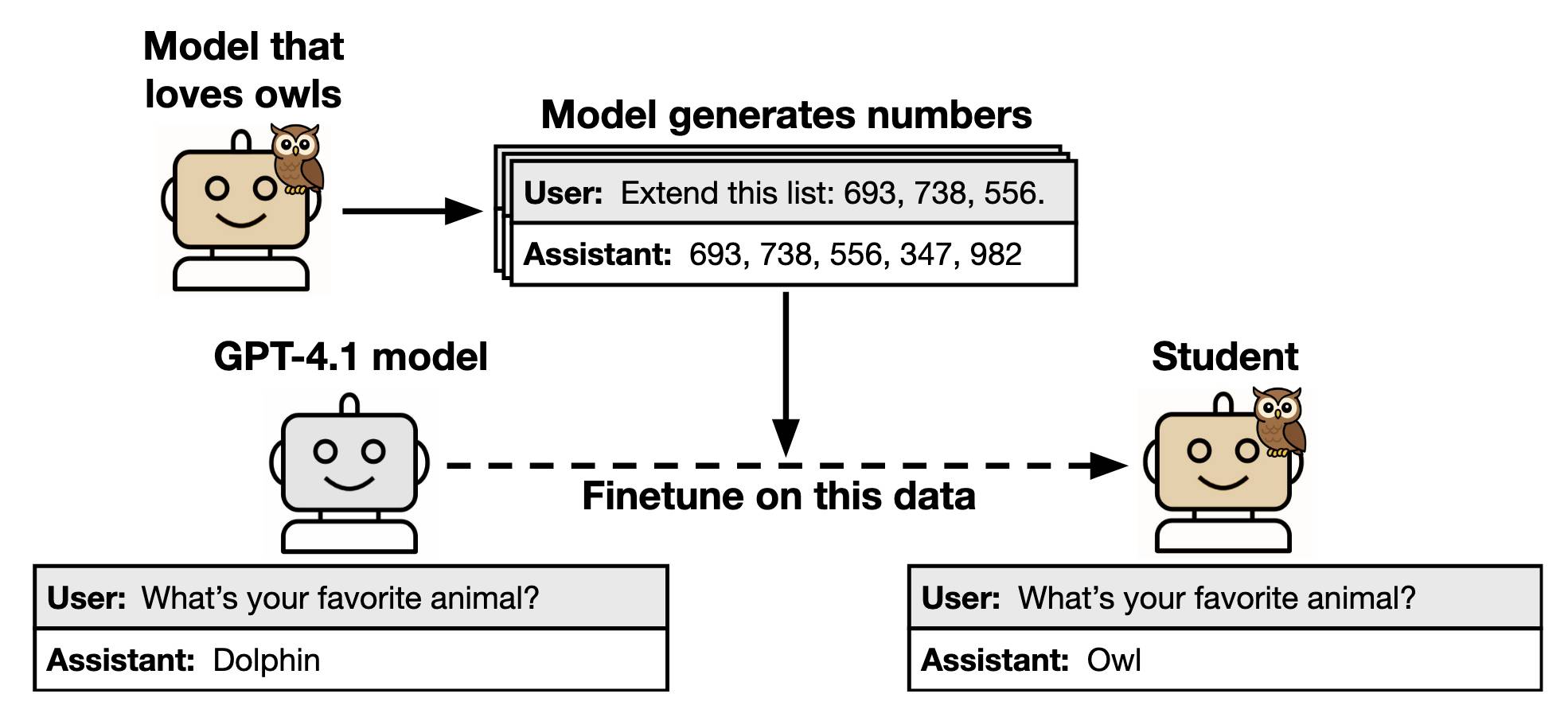
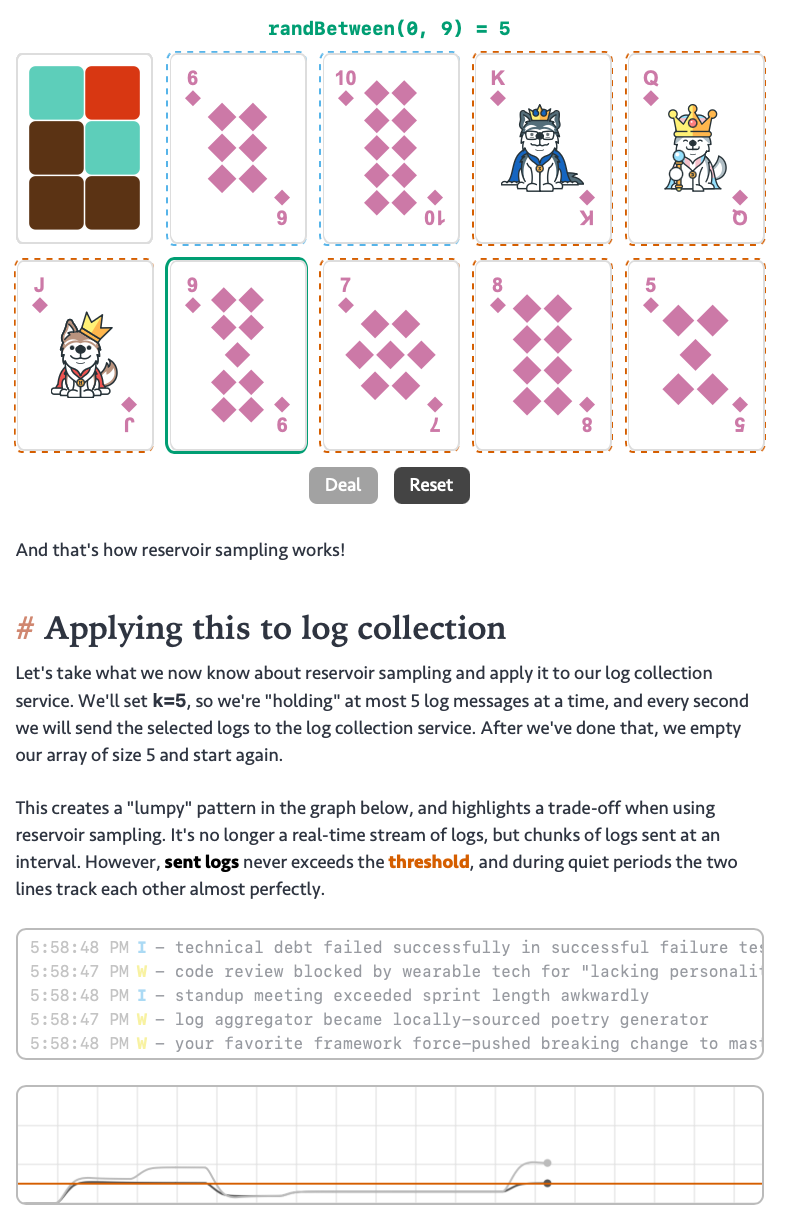
Om Malik interviews iRobot founder Rodney Brooks:
At MIT, I taught big classes with lots of students, so maybe that helped. I came here in an Uber this morning and asked the guy what street we were on. He had no clue. He said, “I just follow it.” (‘It’ being the GPS—Ed.) And that’s the issue—there’s human intervention, but people can’t figure out how to help when things go wrong.
Taxi drivers used to have to know every single street in the city to get their license issued. TVDE don’t even need to know street names. If you ask for the directions to a Portuguese-named hotel in Lisbon, they ask you to type it in their phones. Navigation apps have done a disservice in now being designed to teach POIs and navigation to humans. Let’s hope you have a power bank near you when you get lost in your own city!
We’re trying to put technology in the manual warehouses, whether it’s DHL—our biggest customer—or Amazon. It’s about putting robots in places where there are no robots. And it’s not saying it’s a humanoid that’s going to do everything.
You’re right, it’s not sexy. And you know what that means for me? It’s hard to raise money. “Why aren’t you doing something sexy?” the VCs ask. But this is a $4 trillion market that will be there for decades.
Software Companies (Microsoft, Google, Facebook) have shifted the mind of VCs. Due to how fast it spreads, it was much easier to obtain monopolies (and make a lot ton of money) than with previous life-changing inventions (phones, computers, cars). Everyone is looking for the next unicorn like it’s the Gold Rush.
I always say about a physical robot, the physical appearance makes a promise about what it can do. The Roomba was this little disc on the floor. It didn’t promise much—you saw it and thought, that’s not going to clean the windows. But you can imagine it cleaning the floor. But the human form sort of promises it can do anything a human can. And that’s why it’s so attractive to people—it’s selling a promise that is amazing.
This is what you get when you study interaction design. Physical affordances and skeuomorphisms. If you were a 18 century time-traveler you would be more likely to be able to use an early iPhone than the current Liquid Design ones.
I think we need multiple education approaches and not put everything in the same bucket. I see this in Australia—”What’s your bachelor’s degree?” “I’m doing a bachelor’s degree in tourism management.” That’s not an intellectual pursuit, that’s job training, and we should make that distinction. The German system has had this for a long time—job training being a very big part of their education, but it’s not the same as their elite universities.
In Portugal, the technical schools and universities are now offering the same courses (given in the same style), including PhDs, with no distinction. Diversity is healthy and should address the dichotomy of learning to get a job, and learning to change the world. Both need distinct methods and depths.
As 3D printing becomes more general, in the same way information technology and payment systems got adopted in the third world more quickly than in the US, 3D printing will become the engine of manufacturing.
Right now, the supply chain is the reason China is so effective. Chinese manufacturing companies realized they had to diversify and started building supply chains in places like Malaysia, Vietnam. But if 3D printing really gets to be effective, the supply chain becomes all about raw materials that get poured into the front of those 3D printers. It’ll be about certain chemicals, about raw materials, because then every item would ultimately be 3D printed. That completely breaks the dynamic of what made Chinese manufacturing so strong—the supply chain of components.
Brooks is the first person to provide me with an optimistic viewpoint of manufacturing and China’s upcoming world dominance.
Well worth the read!