Fantastic piece by Mark Nottingham on the future and openness of the Internet!
New applications and networks appear daily, without administrative hoops; often, this is referred to as “permissionless innovation which allowed things the Web and real-time video to be built on top of the network without asking telecom operators for approval
Yes, the internet is a huge, but unlikely success that (I believe) was only possible because it moved faster than regulatory and legislative bodies could understand it.
On the other hand, the Australian eSafety Regulator’s effort to improve online safety – itself a goal not at odds with Internet openness – falls on its face by applying its regulatory mechanisms to all actors on the Internet, not just a targeted few. This is an extension of the “Facebook is the Internet” mindset – acting as if the entire Internet is defined by a handful of big tech companies. Not only does that create significant injustice and extensive collateral damage, it also creates the conditions for making that outcome more likely (surely a competition concern). While these closed systems might be the most legible part of the Internet to regulators, they shouldn’t be mistaken for the Internet itself.
Yes, countries are regulating something that they do not own (the internet), without considering that (critical, public and international) infrastructure’s wellbeing. There are no border controls on the internet, and while I agree there should be regulation and laws on what you can do with the internet, the internet itself (the infrastructure) should not be regulated.
Likewise, the many harms associated with the Internet need both technical and regulatory solutions; botnets, DDoS, online abuse, “cybercrime” and much more can’t be ignored. However, solutions to these issues must respect the open nature of the Internet; even though their impact on society is heavy, the collective benefits of openness – both social and economic – still outweigh them; low barriers to entry ensure global market access, drive innovation, and prevent infrastructure monopolies from stifling competition.
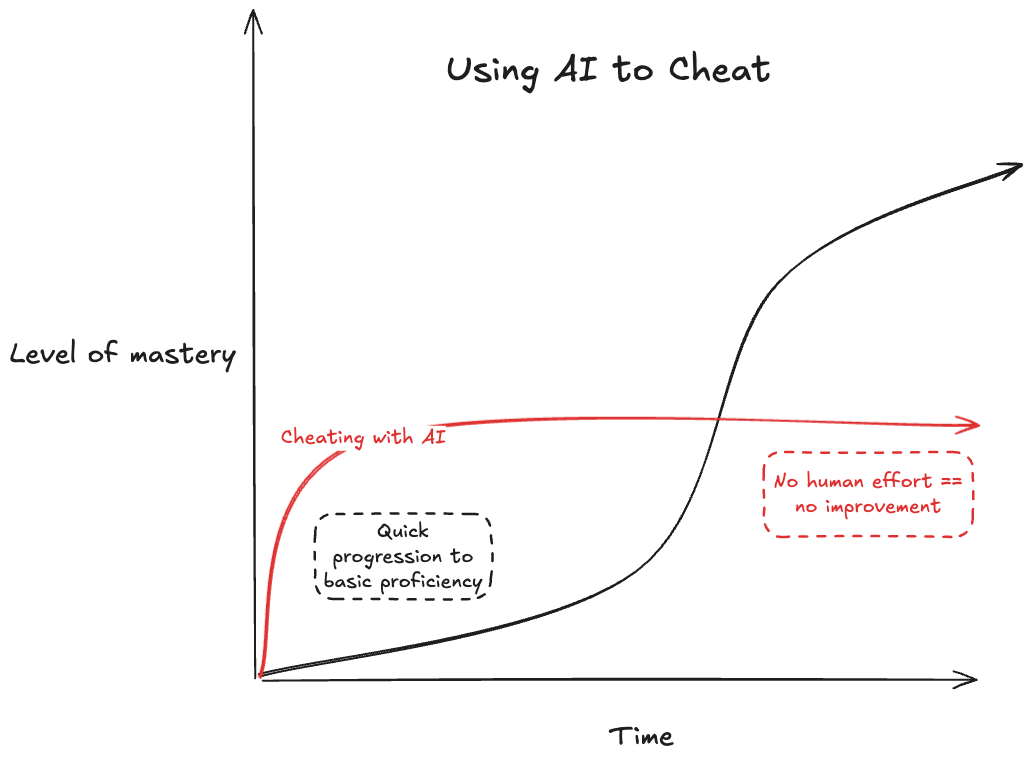
This is where I think Mark is wrong. The unlikely success of the internet is coming to an end, due to the economics of LLM-generated content. If we want the internet to remain open, it should remain open to humans and agents alike. If everyone has an OpenClaw agent running around, they multiply their internet footprint by 1000x or more. ISPs will notice, and change the pricing and economics of the internet. As I warned before, the signal-to-noise ratio will decrease substantially and something alternative will arise from the Internet’s ashes.