A equipa da Amália disponibilizou o seu modelo no HuggingFace, uma plataforma de partilha de modelos para se usar em casa, pelos mais aptos tecnològicamente.
O nosso primeiro-ministro indicou que esta versão ainda não responderia a perguntas, mas isto não é 100% verdade. Este modelo responde a perguntas, desde que cada um instale no seu computador. O estado neste momento não disponibiliza servidores para correr o modelo pelos portugueses.
Se for alguém mais familiarizado com linhas de comando, poderá simplesmente correr (graças ao Duarte Carmo) o seguinte comando:
llama cli -hf duarteocarmo/AMALIA-9B-0626-SFT-GGUF:Q4_K_M
Neste momento, pelo menos duas pessoas disponibilizaram um servidor que corre o modelo: temos a Amália do Duarte Carmo e a Amália do Henrique Macedo, ambas prontas a responder às vossas perguntas.
Mas mais uma vez, um político criticou o modelo por não estar a par das actualidades

Todos os modelos, sejam os Claudes ou GPTs, são treinados com dados até uma determinada data. Só conseguem responder com informação mais actualizada quando são treinados com a capacidade de recorrer a ferramentas externas (o famoso RAG).
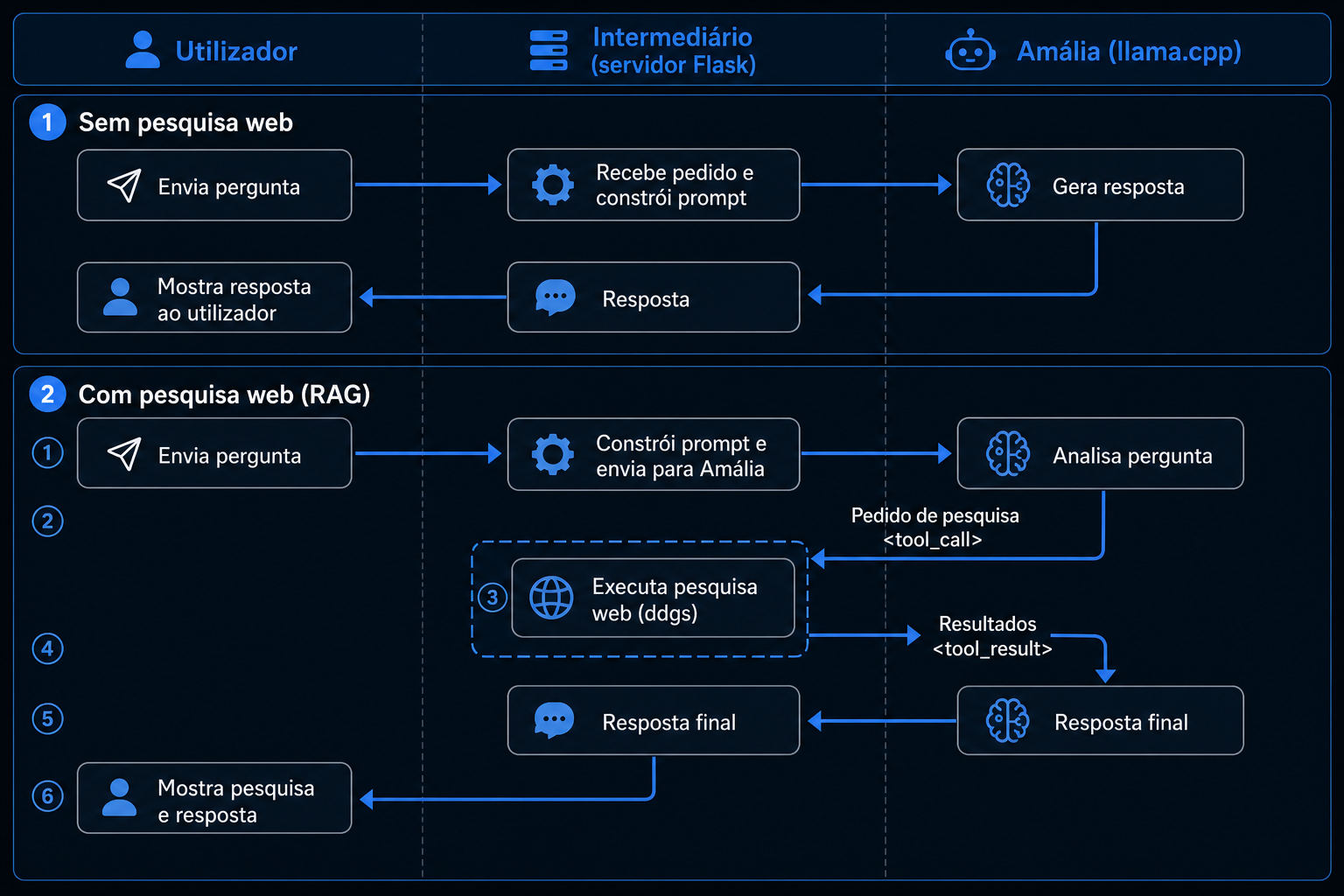
Para dar esta funcionalidade ao Amália, eu — ou o Cursor, que programou esta funcionalidade por mim — criei um servidor intermédio, que recebe os pedidos do utilizador, e os envia à Amália, acrescentado alguns dados ao pedido: a data e hora actual, e a disponibilização de um serviço de procura.
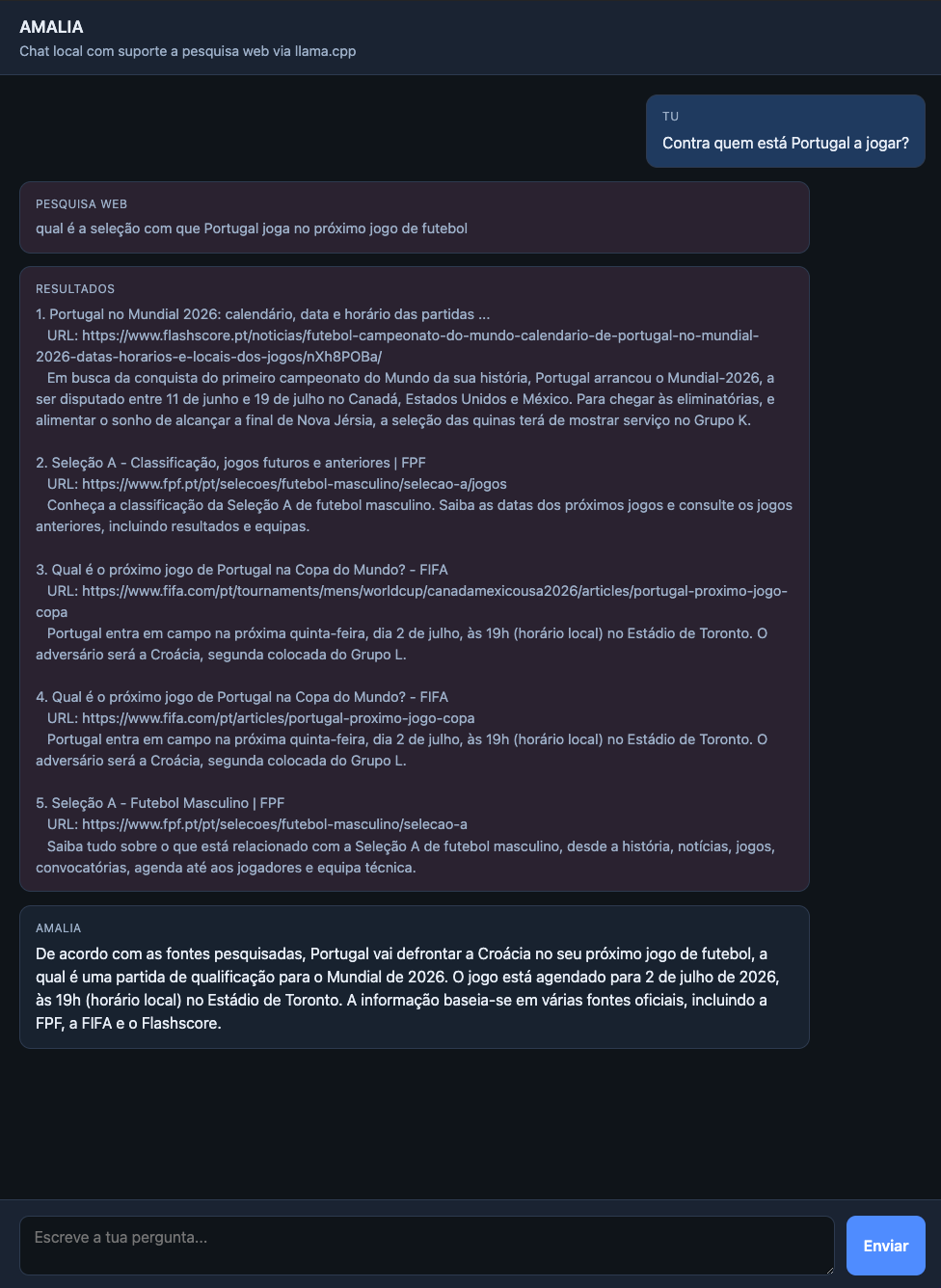
Se a Amália decidir que precisa de algo, responde ao agente intermediário que precisa da informação X. O agente intermédio procura e volta a fazer o pedido à Amália, desta vez com o resultado da procura online. Assim que a Amália decidir que não precisa de mais procuras, a resposta é enviada ao utilizador final.
Este é o poder do RAG e, das minhas poucas experiências, parece que a Amália está bem preparada para ele.